When Not to Fail Fast?
Fail Fast tells you how to move. It doesn't tell you what to check before you start. The cases where those questions go unasked don't just fail fast. They fail wide, quietly, and at someone else's cost.
Fail Fast tells you to ship small, learn quickly, and adjust. The logic is clean: by working in short cycles, you reduce the cost of being wrong. Test the idea before you invest in it. Iterate toward the truth. Keep the loop tight. For a wide range of product decisions, this is exactly the right instinct.
What it doesn't tell you is that the whole model rests on a hidden assumption, one so fundamental that nobody usually bothers to state it: that the cost of failure is low, and that you will know when you've failed.
In certain conditions, both of those things are true. In others, neither is. And the methodology gives you no way to tell the difference.

The Hidden Assumption
Before we get to what goes wrong, pause on the assumption itself.
Imagine a residential building that collapsed on the first drop of a water leak. Would that be acceptable? Of course not. But technically, it failed fast! The problem revealed itself quickly. The feedback was immediate. So why does that sound absurd when we say it out loud?
Because we instinctively understand that the cost of failure matters. A building collapse isn't a learning opportunity. It's a catastrophe. And no one would hand an architect a methodology that treated those two things the same.
Yet in software, we do exactly that. We take a methodology designed for low-cost, recoverable failure and apply it across every kind of system we build, including the ones where the cost of failure is not low, not recoverable, and not visible until long after the damage is done.
That's the gap. Not in the methodology itself, Fail Fast works in the right conditions. The gap is in the question it was never designed to ask: what kind of system am I actually in?
Underneath that question are three others the loop has no mechanism for:
What is failure? Who defined success, and whose interests did they leave out?
Who is failing? When the experiment doesn't work, whose cost is it? The team that ran it, or the people who were inside it?
Who learns, and when? Teams eventually learn what went wrong, but the learning arrives after the harm and almost never reaches the people who paid for it.
These aren't separate critiques. They are the same problem from three angles. The cases below aren't all failures of fast iteration, but they are all failures that a Fail Fast culture, moving confidently inside an unexamined success definition, is structured to replicate.
Question 1: What Is Failure, Actually?
Failure is the inverse of success. Before you can talk about failing fast, you have to ask who defined success and what they left out.
This almost never happens explicitly. The success criterion gets set quietly, and then the Fail Fast loop runs inside it, optimising for something nobody stopped to examine.
The Therac-25 was built to treat cancer. Radiation therapy works by targeting tumours with precisely calibrated doses, enough to destroy malignant cells, not enough to kill the patient. The team behind it defined success as software capability with cost reduction as a downstream benefit. Previous versions had hardware interlocks. These were physical failsafes that prevented the machine from firing at dangerous power levels. The redesign removed them, replacing them with software-only safety checks. Between 1985 and 1987, at least six patients received massive radiation overdoses. At least 3 died.
I came across this case during research and it stopped me. My father underwent radiation therapy. I remember standing in the treatment room at Homi Bhabha Cancer Hospital and Research Centre, New Chandigarh, looking at the machine—enormous, clinical, daunting—and thinking about what it meant to place complete, involuntary trust in a system. The patients who died in Therac-25 incidents were not unlucky. They were inside a system whose definition of success had already excluded them before they ever walked through the door.
The 737 MAX was Boeing's answer to a fuel-efficient competitor. Rather than design a new aircraft, they modified an existing one, moving the engines forward and higher to accommodate larger, more efficient turbines. That change altered the plane's aerodynamics. MCAS was the software fix: a system designed to automatically push the nose down if it detected the plane pitching too steeply. Boeing defined success as not requiring pilot retraining, because retraining would cost airlines money. So MCAS was downplayed in training manuals. 346 people died across two crashes.
In each case, the definition of success excluded the people most at risk. That exclusion wasn't malicious. It was structural, the quiet result of which interests were in the room when the success criterion was set and which weren't.
Think about your own product. Who defined the success criteria? And whose interests weren't in that conversation?
Question 2: Who Is Failing?
Here is a list of metrics most product teams are optimizing for right now:
- Stickiness
- Retention / Churn
- Session Frequency
- Session Length
- Total Time Spent in Product
- Video View-Through Rate
- Engagement Rate
- Stay-to-Swipe Ratio
Look at that list carefully. Every single metric measures the product's performance. Not one measures what is happening to the person using it.
Users aren't stakeholders in this model. They're the raw material.
Tristan Harris, former Design Ethicist at Google and co-founder of the Center for Humane Technology, described the incentive progression in Senate testimony: first you optimise for screen time, then you add social validation loops—likes, followers, the architecture of being seen. Then you build algorithms that identify the specific content triggering each user's individual insecurities. Each step is a Fail Fast success. The product learns faster. The user pays the price.
Facebook is where this plays out in full. They defined success as engagement. The algorithm learned—efficiently, iteratively, exactly as designed—that targeting users' insecurities kept them on the platform longer than connecting with friends did. Internal research, later disclosed by whistleblower Frances Haugen, showed this was also linked to teen anxiety, depression, and distorted self-image. That part never appeared on the OKR dashboard.
In 2018, they tried to fix it. They shifted their primary KPI from "Time Spent" to "Meaningful Social Interactions" (MSI). It sounded right. But because the underlying mechanic was still engagement-driven, MSI inadvertently amplified outrage and polarising content. Those posts generated the most reactions and shares. The metric changed. The harm accelerated. Facebook's own researchers documented this and named it clearly.
You can't solve a Who problem with a What fix.
If the users aren't inside your definition of success, changing the success metric doesn't change the underlying structure.
There's a simpler way to see this. Imagine if we gave children nothing but candy for food, and made healthy food expensive and hard to find. By certain metrics, that looks like a successful food system: high consumption, low unit cost, strong retention. The children keep coming back. What it does to a generation is obvious the moment you say it out loud.
Social media engagement algorithms work on the same logic. The cheapest, most stimulating content at zero friction. Deep focus, real connection, genuine rest; all made to feel effortful by comparison. The product succeeds. The human pays the difference. And the Fail Fast loop, running cleanly the entire time, never registers any of it as failure.
Question 3: Who Learns, and When?
Teams do eventually learn what went wrong. That part of the Fail Fast loop functions as promised. The problem is the sequencing: the learning arrives after the harm, not before it. And moving fast inside a broken feedback loop doesn't just fail to prevent that delay. It accelerates toward it. Even then, the learning almost never crosses the gap to the people who paid for it.
In the physical world, this accountability is enforced before anything is built. If a company wants to construct an oil pipeline, it has to announce the route, the environmental impact, the dimensions, and the timeline. Mandatory transparency exists because the harm is visible. You can see the land. You can see the people. The blast radius is undeniable, so the learning has to happen in advance, not in the aftermath.
In software, the harm is invisible. Mental health doesn't have a GPS coordinate. When a product team learns that a notification pattern correlates with late-night usage in teenagers, that learning stays in the analytics dashboard. It gets weighed against the engagement lift. The people being affected never learn why the product was designed to work on them the way it does.
Facebook's internal researchers documented the MSI problem in detail. That knowledge existed inside the company for three years before Frances Haugen took it to Congress. The learning happened. It just never crossed the gap.
The Therac-25 shows what delayed learning looks like at the operational level. Before the deaths, the machine had been generating a cryptic error—Malfunction 54—hundreds of times a day. The operators were learning in the way all systems teach us: through repetition and the absence of immediate consequence. They hit proceed. Nothing catastrophic happened. They learned that proceed was safe. Until the day it wasn't.
Sociologist Diane Vaughan gave this pattern a name after studying the Challenger disaster: normalization of deviance. The O-rings (rubber seals in the solid rocket boosters) responsible for containing combustion gases during launch, had been showing damage after flights. Each time the shuttle returned safely, management noted the damage and cleared the next flight. Not because they ignored the data. Because the data kept producing safe outcomes. The engineers knew. Roger Boisjoly had been documenting the risk for months, and the night before the launch, the engineering team explicitly recommended against it. Management overruled them. On January 28, 1986, the organisation's accumulated tolerance for deviation converged. The feedback was never incomplete. The structure just gave the final word to the wrong people.
Now ask: does any version of this sound like a product review you've been in? An edge case affecting "less than 2% of users" deprioritised quarter after quarter. A user harm signal that never gets addressed because there's no OKR attached to it.
This is how deviance normalises in software. Not with a dramatic decision. With a hundred small ones, each of which produced the wrong lesson at the right moment.
The Risk Horizon Matrix
The three questions share a structural root. Answering them requires two variables that Fail Fast never asks you to examine before the loop starts:
- How quickly does failure become visible?
- And how far does the damage spread when it does?
These aren't critiques of the methodology. They're the prerequisite check it assumes you've already done. Map them and you get four fundamentally different kinds of systems, each demanding a different strategy, only one of which is Fail Fast.
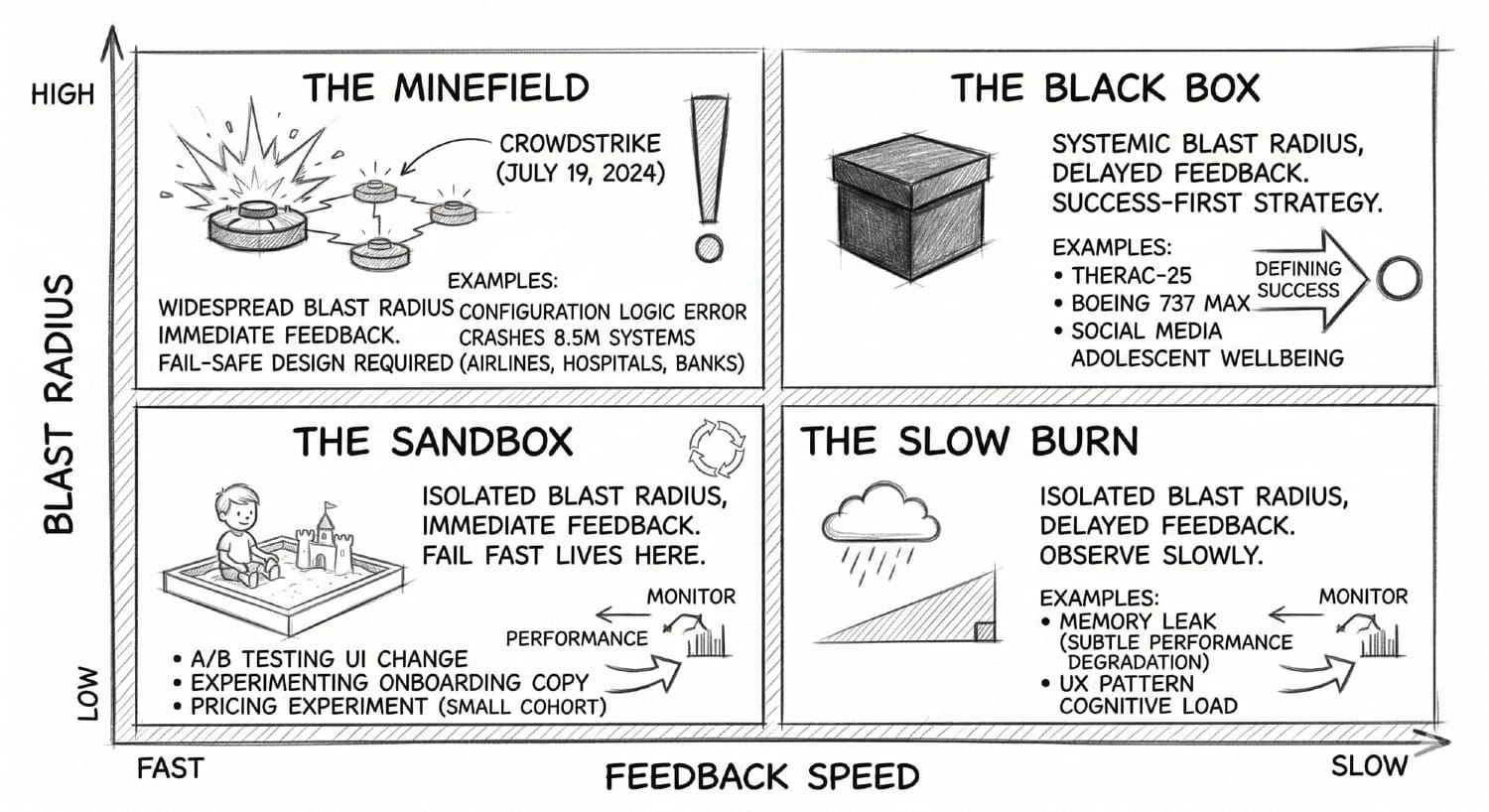
The Sandbox - Immediate feedback, Isolated blast radius
The only quadrant where Fail Fast belongs. Short feedback loop, limited downside. A/B testing a UI change, experimenting with onboarding copy, running a pricing experiment on a small cohort. The signal comes back quickly, the damage is contained if you're wrong, and the loop is honest. Agile was designed for this quadrant. Iterate freely.
The Slow Burn - Delayed feedback, Isolated blast radius
The damage is limited but the feedback loop is long. A memory leak that silently degrades performance for a small user segment over months. A UX pattern that subtly increases cognitive load without triggering any immediate drop in engagement. The absence of an immediate signal is not safety; it's latency. The right move isn't to iterate. It's to *observe slowly*, monitor leading indicators, and build instrumentation that can see into the delay.
The Minefield - Immediate feedback, Widespread blast radius
Failures happen fast and hit everything at once. On July 19, 2024, CrowdStrike pushed a routine content update to its Falcon security software. A logic error in a single configuration file caused 8.5 million Windows systems to crash simultaneously: airlines, hospitals, banks, emergency services, all at once. The signal was immediate. By the time anyone could intervene, the damage was total and the recovery required manual intervention on every affected machine. The right strategy here is fail-safe design: circuit breakers, staged rollouts, hard limits that prevent a mistake from propagating faster than a human can intervene. You are not trying to learn from failure here. You are trying to make sure failure cannot reach everything at once.
The Black Box - Delayed feedback, Systemic blast radius
The most dangerous quadrant, and the one Fail Fast is most catastrophically wrong for. Consequences are slow to surface and catastrophically wide when they arrive. Therac-25. Boeing 737 MAX. Social media's effect on adolescent wellbeing. The feedback loop is so long that by the time your dashboard tells you something went wrong, it has been wrong for years. The only responsible approach is Success-First: define what a good outcome looks like before you build, treat ambiguous signals as threats rather than noise, and accept that some feedback loops are too long to learn from through iteration—which means doing more work before the first experiment, not less.
Most product decisions that touch human behaviour, attention, identity, or wellbeing at scale live in the Black Box. The feedback loop is long. The blast radius is generational. And the Fail Fast culture has almost no vocabulary for it.
What Success-First Actually Looks Like in Product
Aerospace, medical devices, nuclear power—industries that can't iterate their way out of a Black Box failure—developed a different instinct entirely. Not caution for its own sake. A genuine preoccupation with failure before it happens.
Researchers Karl Weick and Kathleen Sutcliffe studied these high-reliability organisations for decades and found they shared five habits that product teams almost never practise:
- They hunted for bad news rather than waiting for it to surface.
- They treated early warning signals as gifts, not noise to deprioritise.
- They rewarded people for raising problems before they became systemic.
- They resisted simplifying the picture when it got complicated.
- In a crisis, authority went to whoever had the most relevant knowledge, not the highest title.
Read that list and think about your last product review. A user harm signal soft-pedalled because the feature had leadership buy-in. An edge case dismissed because it only affected 2% of users. A warning in the data that nobody had an OKR to act on.
That gap, between how HROs treat signals and how product teams treat them, is the practical difference between Safety-I and Safety-II thinking.
Safety-I asks: how do we make sure as few things as possible go wrong? This is where most product analytics lives. Post-mortems. Bug tracking. Churn analysis. Find what broke, patch it.
Safety-II asks: how do we make sure as many things as possible go right? Under what conditions do users genuinely get value from this product? What does a successful session look like for them, not the dashboard? How do we build more of those conditions?
The shift matters because in a Black Box, Safety-I only tells you what happened. By then, it's already too late.
For product teams, this translates into two practical moves:
The Regret Test: Nir Eyal draws a line between persuasion and coercion in Hooked. Persuasion is helping people do things they already want to do. Coercion is getting them to do things they didn't want to do. The test is one question: does the user feel regret after? If the answer is yes, consistently, at scale, you are not failing fast and learning. You are succeeding at the wrong thing.
Jobs NOT to Be Done: The Jobs To Be Done framework asks what job a user is hiring your product to accomplish. The version almost no one asks: what are the jobs the user is hiring this product not to do?
- I do not want to spend three hours here when I meant to spend ten minutes.
- I do not want to feel worse about myself after opening this app.
- I do not want my child to learn that comfort and safety come from a screen.
These aren't edge cases. They are the unspoken terms of the contract between a product and the people using it. No OKR, no sprint metric, no dashboard captures them. Which is exactly why they keep getting violated.
When Not to Fail Fast?
Here is the plainest version of the answer.
Don't fail fast when you can't honestly close the feedback loop on the people absorbing the cost.
If the damage surfaces in mental health and the metric shows engagement, if the risk accumulates invisibly and the dashboard shows green, the loop is lying to you. Iterating inside a dishonest feedback loop doesn't produce learning. It produces confidence in the wrong direction.
Don't fail fast when the blast radius outlasts your ability to intervene.
If a failure at this speed would propagate faster than a human can stop it, or spread more widely than a sprint retrospective can address, you are not in the Sandbox. You are in the Minefield or the Black Box. The speed that makes Fail Fast valuable in one context makes it catastrophic in another.
Don't fail fast when the people at risk aren't in the room when you define success.
This is the root of every case in this essay. Not malice; structure. The Therac-25 engineers were not careless. Boeing's engineers were not villains. Facebook's product team was not indifferent. They were all inside systems whose definition of success had quietly excluded the people most at risk, long before anything went wrong.
So, What Do You Do With This?
Building responsibly is not the same as building slowly. It is not about being afraid to ship.
It means mapping your system before choosing your strategy. Knowing which quadrant you're in before you decide how fast to move. Asking, before the sprint starts, not after the post-mortem: if this fails, who absorbs the cost, and will they ever know why?
It means treating user harm signals the way high-reliability organisations treat early warning signals: not as noise to deprioritise, but as data the system is trying to surface before the damage compounds.
I previously wrote about how hustle culture makes the machine the point, not the people running it. Fail Fast is what that culture looks like when it becomes a development methodology. The same logic. The same fear underneath. Now with a framework attached.
But it does change the questions you ask.
Before you define the success metric: whose interests aren't in this room?
Before you run the experiment: if this fails, who absorbs the cost—and will they ever know why?
Before you hit proceed: what kind of system are you actually in?
Further Reading
Final Committee Report: The Boeing 737 MAX: US House Committee on Transportation and Infrastructure (2020). The 238-page congressional investigation into the design, certification, and cultural failures behind the two crashes that killed 346 people. The source on production pressure, pilot retraining decisions, and Boeing's withholding of MCAS information.
Frances Haugen Written Testimony: US Senate Commerce Subcommittee on Consumer Protection, October 2021. The primary source for Facebook's internal research on harm to teenagers, the MSI experiment, and the three-year gap between internal knowledge and public disclosure.
Tristan Harris Senate Testimony: US Senate Commerce Committee, June 2019. The source for the incentive progression described in Question 2 — from screen time to social validation loops to algorithms targeting individual insecurities.
EU Artificial Intelligence Act: Regulation (EU) 2024/1689, European Parliament, June 2024.
2024 CrowdStrike Outage: A detailed account of the July 19, 2024 incident: the logic error in a single content update that crashed 8.5 million systems simultaneously across airlines, hospitals, banks, and emergency services.
The Therac-25 Case Study: Ethics Unwrapped, University of Texas. The clearest account of how engineer overconfidence and ignored operator reports led to patient deaths.
The Challenger Launch Decision: Diane Vaughan, University of Chicago Press (1996). The foundational work on normalization of deviance and how organisations incrementally accept risk until it converges.
Managing the Unexpected: Karl Weick & Kathleen Sutcliffe, Jossey-Bass (3rd ed. 2015). The source on high-reliability organisations and the five principles that separate teams that catch failure early from those that don't.
Hooked: The canonical text on habit-forming product design — and the source of the persuasion vs. coercion distinction and the Regret Test.
Canada's Algorithmic Impact Assessment: — Government of Canada. The mandatory pre-deployment impact assessment framework for automated decision systems.