Why Does Your Team Keep Shipping and Missing?
Your team shipped. The metrics didn't move. The retro produced action items. None of it helped. Here's why.
I have sat in both rooms.
The engineering retro and the product post-mortem. Different vocabulary, different teams. But the physics of failure are always the same.
On the Product side, the launch was successful but the metrics are flat. On the engineering side, the technical debt was paid, but nobody knows what that means for business.
This then gets justified by statements like:
"It takes time for users to change their behavior." — PM
"This code is easy to maintain now." — Devs
Both are conclusions. Neither is an investigation.
The team runs a retrospective. Root causes get identified. Rushed rollout, unclear messaging, scope cut close to the launch. Action items get writted. Everyone commits to better sprint planning, clearer briefs, and a proper launch checklist.
Six months later, they ship again. Better processes. Tighter execution. Metrics still flatline like a patient who's past the point of resuscitation.
The problem wasn't in the execution. It was in the conclusion.
The Causal Stack
When you're having a heart attack, your left arm hurts.
Not your chest. Not your heart. Your arm.
It's because the heart and the left arm share the same nerve pathways into the brain. When the heart is starved of oxygen and sends out distress signals, the brain receives them, but it can't pinpoint the exact source. It knows the signal came from somewhere in that network. So it does what brains do with ambiguous information: it makes a guess. The guess is the arm.
The arm is fine. The heart is dying. The pain is real. The location, wrong.
Nearly 40% of heart attack patients experience no chest pain at all. Just the arm. Or the jaw. Or an unusual fatigue that feels like flu. With no obvious chest signal to follow, many of them visit an orthopaedic doctor, or worse, take an over the counter medicine for the fatigue. They conclude it's not serious. The real problem goes untreated, not because they couldn't find the answer, but because they stopped looking too early.
Product and engineering failures work the same way. The metrics land. The room reacts. The teams jump to conclusions without questioning whether those observations actually explain the failure or just describe it.

To get to it, you need to rewind. There are three layers where a failure can originate. Together they form what I call The Causal Stack.
The Stack, Layer by Layer
The Bet Layer: What problem are we actually solving?
If we solve this problem, this outcome will follow.
For product teams this is where a hypothesis is made. If we solve this problem for this customer, this outcome will follow. For engineering teams this is the tech strategy — or more often, the absence of one. Engineers are trained to fix things. Measuring how a fix actually moves the needle is rarely part of the job description.
A team bets that simplifying onboarding will improve market share. The assumption, that friction is the primary reason users aren't converting is never tested. The bet was pointing at the wrong stage entirely.
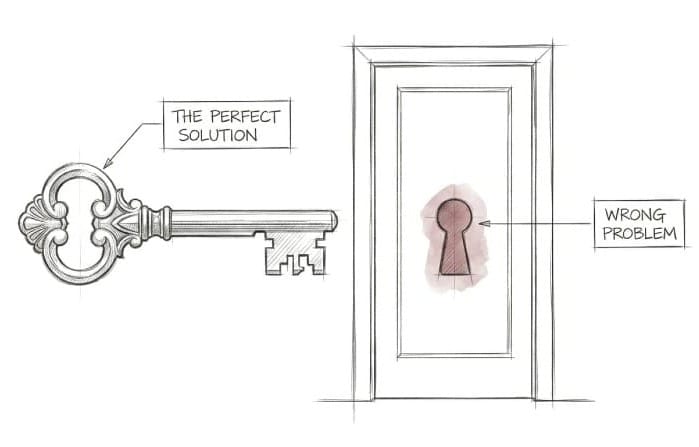
An engineering team bets that breaking a monolith into microservices will improve deployment velocity. The assumption, that architecture is the bottleneck is never tested. Features still require manual cross-team coordination to launch. The bet was pointing at the wrong door.
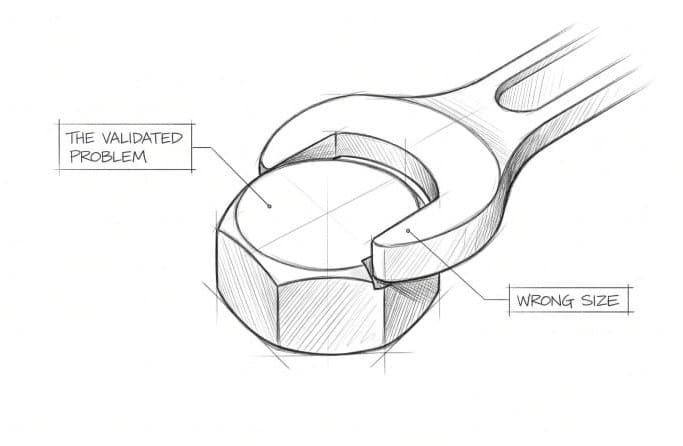
The Roadmap Layer: What solution did we actually choose and why?
This is where you decide how to pursue the bet. For product teams, this is solution selection. Which feature, which approach, which trade-off. For engineering teams, this is the prioritization of debt and technical work. Without a clear bet as a north star, prioritization defaults to the loudest voice or the easiest ticket.
A team building a new onboarding flow removes steps because it's faster to build when the drop-off was actually caused by users not understanding the product's value before committing. Right problem. Wrong solution.
An engineering team spends a quarter refactoring a service that engineers find frustrating but that nobody actually waits on, while the flaky test suite causing most deployment delays goes untouched. Right area. Wrong problem within it.
The Execution Layer: Did we actually build what we intended?
This is where you build and ship. Code gets written, designs get finalized, and the launch happens. Leadership commits to a timeline before the team maps the work. Complexity surfaces. Scope gets cut under pressure. What ships is a thinner version of what was designed.
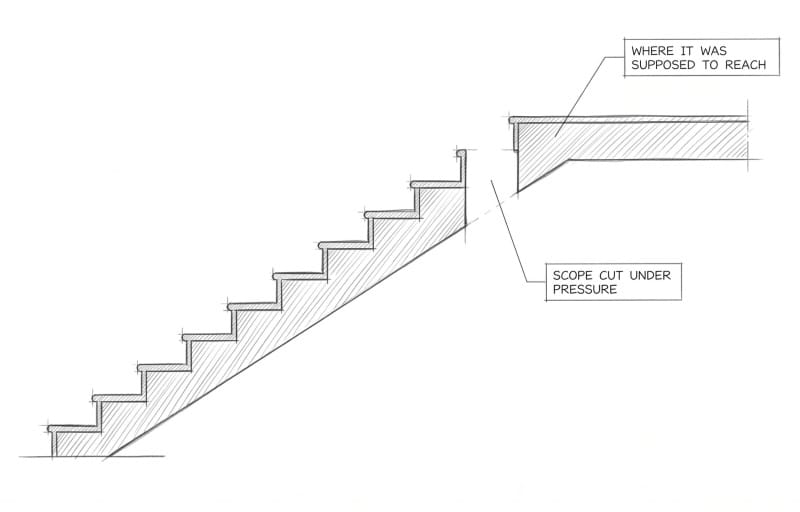
For engineering teams the same failure looks slightly different but comes from the same place. A team takes on a technical initiative without breaking it down properly. Midway through, the work proves harder than expected. Corners get cut. The implementation is technically complete but fails to create impact.
Nobody deliberately ships something incomplete. Execution failures at this layer are almost always a planning failure in disguise.
Why The Conclusion Forms Before Investigation Starts
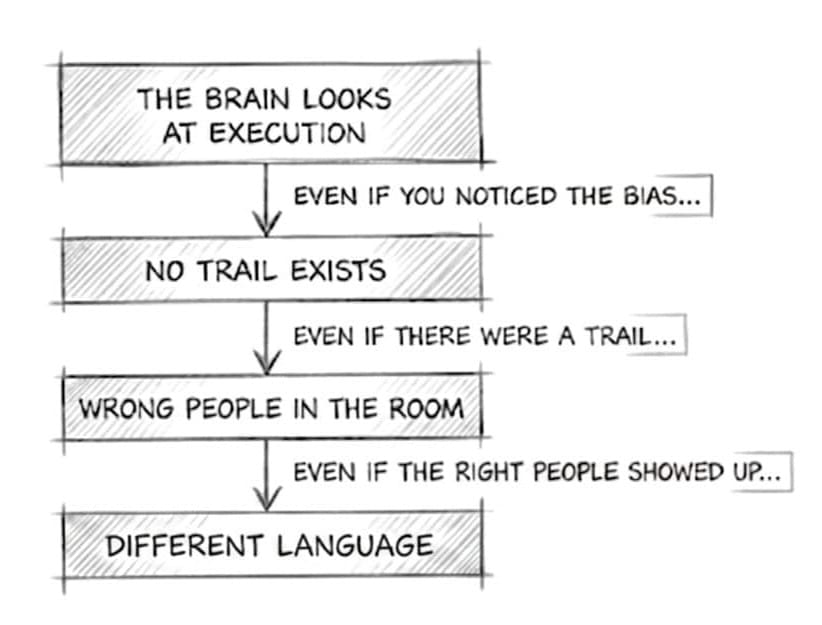
Because four forces work together to make it impossible to investigate the right layer.
- The brain finds the nearest and easiest cause. So the conclusion arrives before the question starts.
- The assumption left no trail. So the conclusion feels justified even when it isn't.
- The people who made the bet aren't in the room. So the conclusion is never challenged by the people who could.
- The layers don't speak the same language. So the conclusion forms in execution vocabulary and never travels upstream.
1. The Brain Finds The Nearest and Easiest Cause
The human brain is wired to find causes close to effects. You touch fire, your hand burns. The cause and the consequence arrive together, and the brain learns the pattern. This is useful. This is how we survive.
Complex systems break this wiring.
In a product organization, a decision made in January can cause a metrics failure in April. Three months of work sit between the cause and the consequence. By the time the failure surfaces, the original decision is buried under so many subsequent choices it has become effectively invisible.
The brain looks for a cause. It finds the most recent thing. It finds the easiest thing to act on. It concludes.
The wiring that kept humans alive for thousands of years was never designed for systems where cause and consequence are months apart.
2. The Assumption Left No Trail So The Conclusion Feels Justified
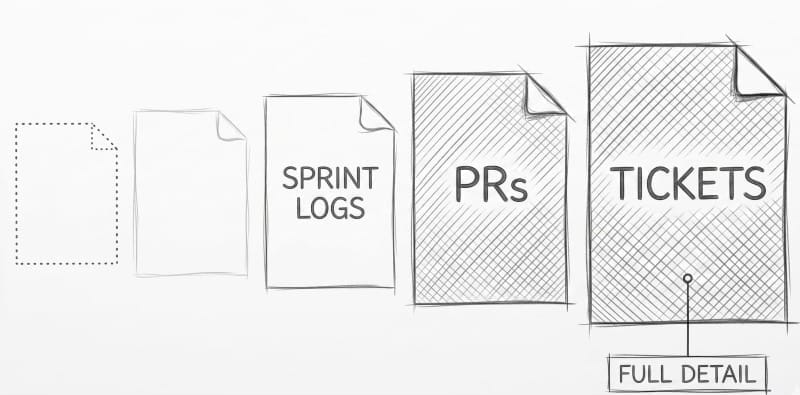
Execution failures have clear owners. The engineer who estimated the work, the PM who cut scope, the designer who signed off on the flow. They are documented in tickets, in Slack threads, in the sprint log. They are discussable because they are locatable.
Strategic assumptions are different in kind, not just in age.
They don't get made in a single meeting. They emerge gradually, across early conversations, in the space between what was said and what was heard, until they become so embedded in a project's logic that questioning them would feel like questioning the leadership itself.
By the time a team is deep in execution, the assumption isn't even visible anymore. There is no ticket to pull up. No decision log to reference.
You can only audit what left a trail.
And sometimes the trail was never even agreed upon. Two people walked out of the same meeting with different beliefs about what was decided. Neither checked. The assumption didn't just leave no trail, it was never fully formed in the first place.
When there is nothing to examine, the conclusion that formed at the surface feels like the only conclusion available.
3. The People Who Could Challenge The Conclusion Aren't In The Room
The retro convenes the people who did the work. The people who set the original direction, who placed the bet, who defined the strategy, are rarely present.

This isn't accidental. The Causal Stack maps directly to the org chart. Each layer is owned by a different tier of the organization. The execution layer is owned by the team. The roadmap layer is owned by product leaders. The bet layer is owned by whoever has the authority to define strategic direction.
A team can only interrogate the decisions it made. The decisions that happened above them are not theirs to examine. And in most organization, not their place to question.
So the retro does what it can. It works with the people present. The conclusion forms at that layer because that's the only layer the room has authority over.
The person who could answer for the bet was three floors up and three projects further along. And even if they were present, the dynamic rarely changes. A leader whose strategic decision is being examined by the team that executed it is an uncomfortable position. Most organizations are not structured to create that conversation, and most people on both sides of it are not incentivized to start it.
The conclusion doesn't just go unchallenged. It becomes unchallengeable.
4. The Layers Don't Speak the Same Language
Each layer of the Causal Stack has its own vocabulary.
- The execution layer speaks in sprints, scope, and tickets.
- The roadmap layer speaks in trade-offs and solutions.
- The bet layer speaks in market hypotheses and strategic direction.
When a concern surfaces in one layer, it rarely lands in the language of another.
Developers say a service is fragile, hard to work with, accumulating risk. What they mean is that this debt is making it impossible to test the bets the product team is placing. The experiment can't run. The feature that should take three weeks will take three months. The bet can't be validated because the infrastructure can't support it.
The case was made in engineering terms. The impact was never translated into the outcome layer where prioritization decisions get made. So the debt stays. The slowdown compounds. The same conversation happens every quarter in the same language and receives the same answer.
The same misalignment runs vertically through the organization. Leadership measures business outcomes — revenue, market share, ARR. Product measures success metrics tied to user behavior — activation, adoption, retention. Engineering measures technical health — uptime, velocity, deployment frequency. Each layer has its own scorecard and its own definition of success.
A product can show improving metrics at every layer simultaneously and still be failing the original bet because nobody is measuring whether the three scorecards are connected. The conclusion forms independently at each layer. Nobody is wrong. Nobody is looking at the same thing.
What Now
The Causal Stack doesn't tell you what to fix. It stops you from concluding before you've looked.
Four forces are working against you every time a metric lands wrong. The brain settles on the nearest cause. The assumption leaves no trail. The people who could challenge the conclusion aren't in the room. And even if they were, they'd be speaking different languages with different scorecards.
The failure might live in one dimension. It might live in all three. You won't know until you've looked at each one.
There is a question that creates that space. One sentence. Before the first action item gets written.
If your last retro produced the same action items as the one before it — you need it.
That question, and what to do with the answer, is where this continues.
Read the next part here:
